Target pipeline¶
Note
These instructions are outdated and only valid for prefactor 3.2 or older. Please check the recent instructions page.
This pipeline processes the target data in order to apply the direction-independent corrections from the calibrator pipeline (line 26). A first initial direction-independent self-calibration of the target field is performed, using a global sky model based on the TGSS ADR or the new Global Sky Model (GSM), and applied to the data.
You will find the single steps in the parameter pipeline.steps in line 99.
This chapter will present the specific steps of the target pipeline in more detail.
All results (diagnostic plots and calibration solutions) are usually stored in a subfolder of the results directory, see inspection_directory (line 71) and cal_values_directory (line 72), respectively.
Prepare target (incl. “demixing”)¶
This part of the pipeline prepares the target data in order to be calibration-ready for the first direction-independent phase-only self-calibration against a global sky model. This mainly includes mitigation of bad data (RFI, bad antennas, contaminations from A-Team sources), selection of the data to be calibrated (usually Dutch stations only), and some averaging to reduce data size and enhance the signal-to-noise ratio. Furthermore, ionospheric Rotation Measure corrections are applied, using RMextract The user can specify whether to do raw data or pre-processed data flagging and whether demixing should be performed.
The basic steps are:
mapping of data to be used (
createmap_target)copying h5parm solution set from the calibrator (
copy_cal_sols)- gathering RM satellite information and writing it into h5parm (
h5imp_RMextract) 
- gathering RM satellite information and writing it into h5parm (
creating a model of A-Team sources to be subtracted (
make_sourcedb_ateam)check of any missing solutions for the target data (
check_station_mismatch)- basic flagging and averaging (
ndppp_prep_target) edges of the band (
flagedge) – only used inraw_flaggingmodestatistical flagging (
aoflag) – only used inraw_flaggingmodebaseline flagging (
flag)low elevation flagging (below 20 degress elevation) (
elev)demix A-Team sources (
demix) – only used if specifiedapplying clock offsets, polarization alignment, and bandpass correction derived from the calibrator (
applyclock,applyPA,applybandpass)applying LOFAR beam and Rotation Measure correction from RMextract (
applybeam,applyRM)interpolation of flagged data (
interp)averaging of the data to 4 seconds and 4 channels per subband (
avg)
- basic flagging and averaging (
write A-Team skymodel into the MODEL_DATA column (
predict_ateam)clipping potentially A-Team affected data (
ateamcliptar)interpolate, average (to 8 seconds and 2 channels per subband), and concatenate target data into chunks of ten subbands (
dpppconcat). These chunks are enforced to be equidistant in frequency. Missing data will be filled back and flagged.wide-band statistical flagging (
aoflag)remove chunks with more than 50% flagged data (
check_unflagged)identify fully flagged antennas (
check_bad_antennas)
Now the data is prepared and cleaned from the majority of bad data.
Phase-only self-calibration¶
These steps aim for deriving a good first guess for the phase correction into the direction of the phase center (direction-independent phase correction). Once this is done, the data is ready for further processing with direction-dependent calibration techniques, using software like factor or killMS.
download global sky model for the target field automatically (
sky_tar)interpolate flagged data and perform direction-independent phase-only calibration (diagonal terms) within a limited baseline range, using the filter (
gsmcal_dysco)
The phase solutions derived from the preparation step are now collected and loaded into LoSoTo to provide diagnostic plots:
ph_freq??: matrix plot of the phase solutions with time for a particular chunk of target data, where both polarizations are colorcoded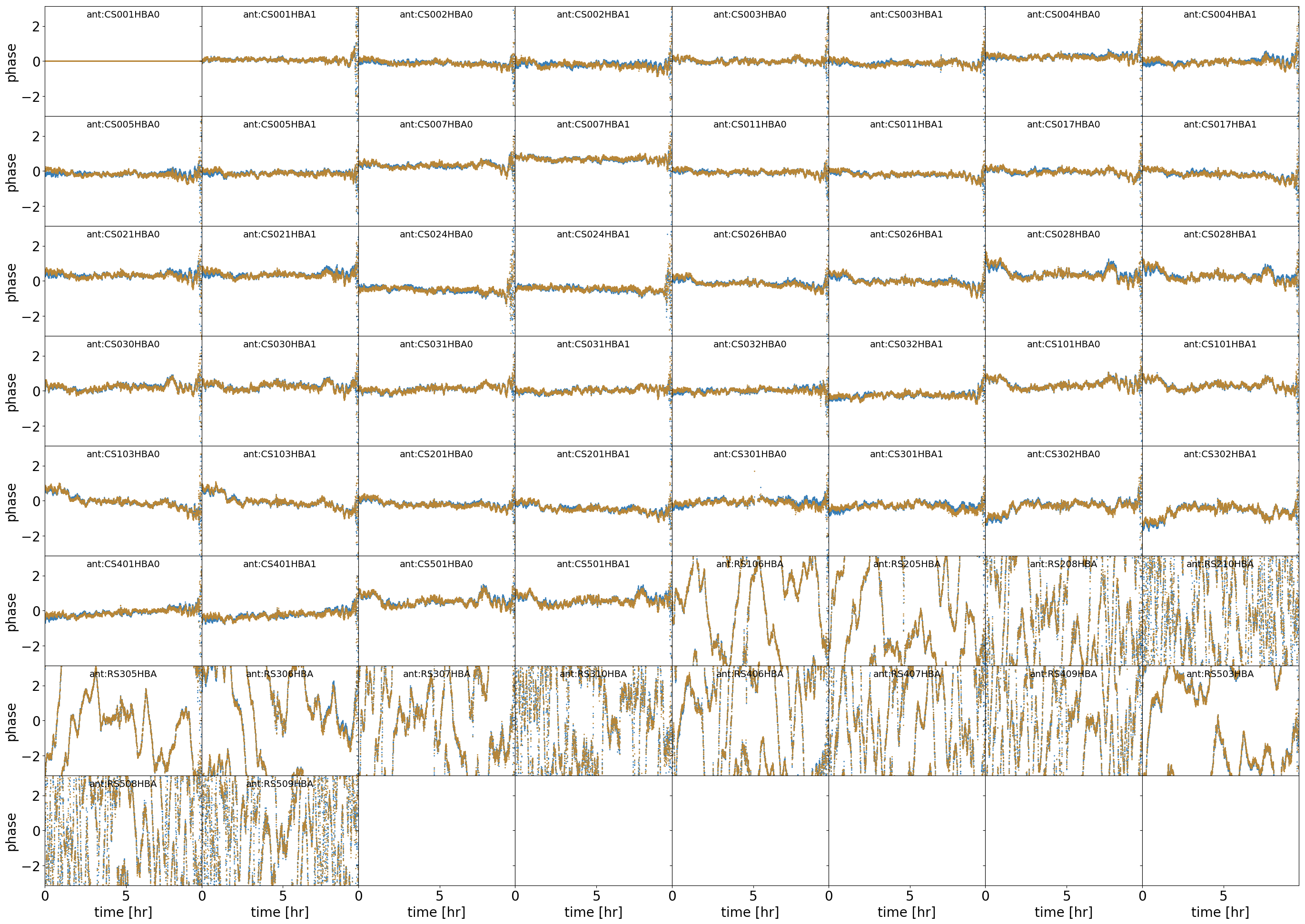
ph_poldif_freq??: matrix plot of the XX-YY phase solutions with time for a particular chunk of target data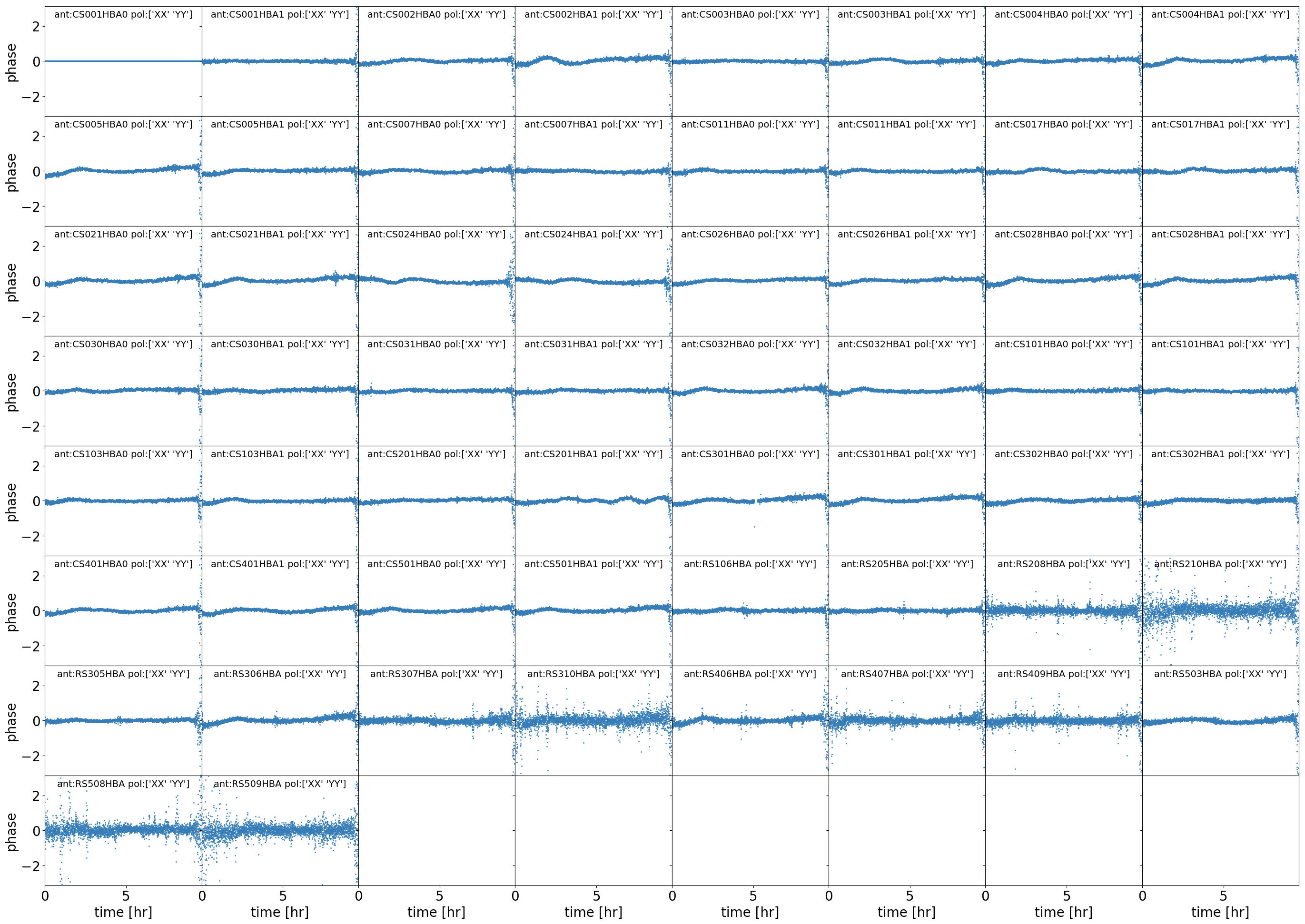
ph_pol??: matrix plot of the phase solutions for the XX and YY polarization
ph_poldif: matrix plot of the phase solutions for the XX-YY polarization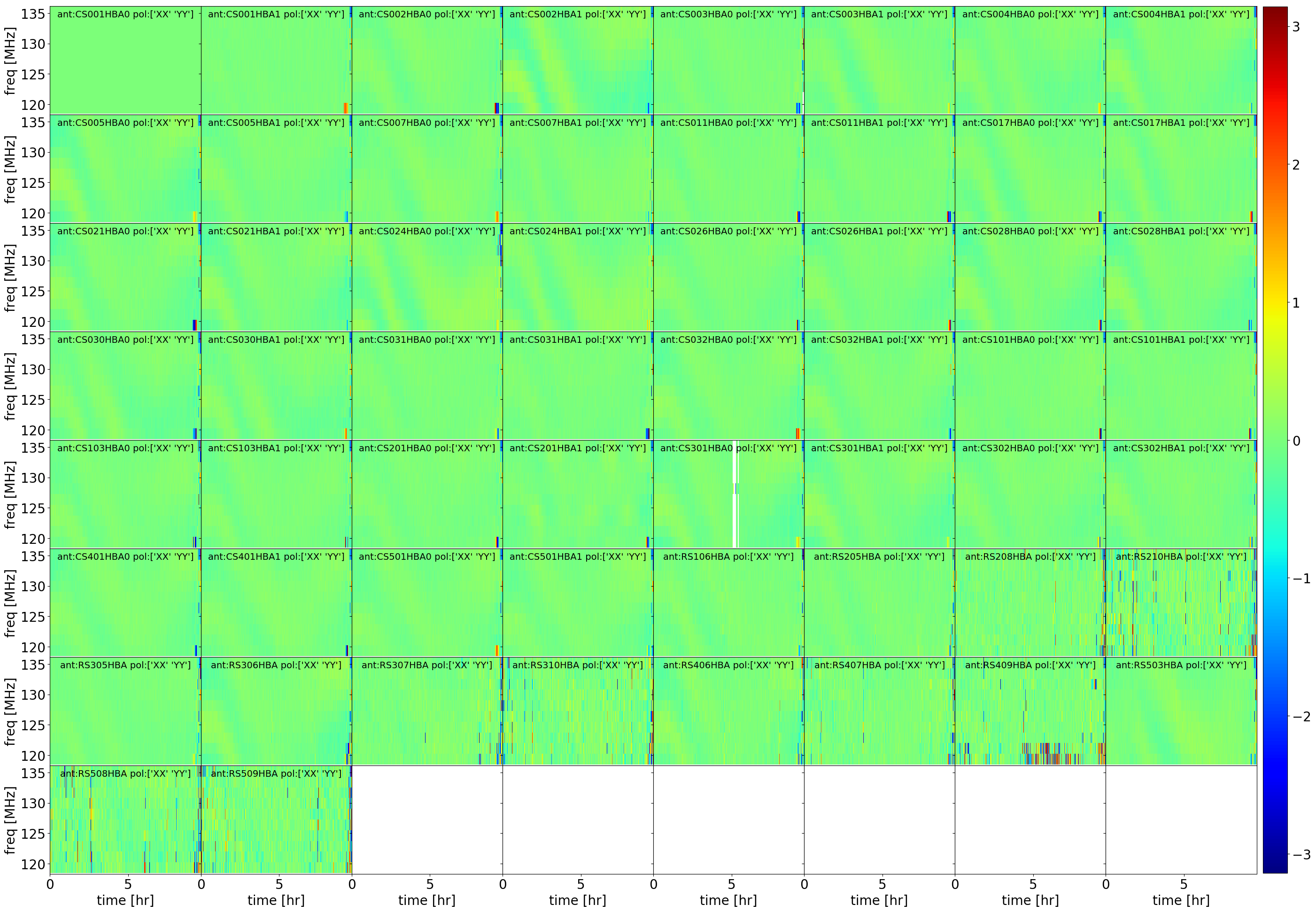
The solutions are stored in the h5parm file format. The last step also incorporates full Dysco compression to save disk space. The fully calibrated data is stored in the DATA column. In the results directory also the uncompressed and uncorrected data is stored. These data are used for the Initial-subtract pipeline.
User-defined parameter configuration¶
Parameters you will need to adjust
Information about the input data
target_input_path: specify the directory where your target data is stored (a full UNIX-compatible directory is required)target_input_pattern: regular expression pattern of all your target files (e.g.L72319*.MS)
Location of the software
prefactor_directory: full path to your prefactor copylosoto_directory: full path to your local LoSoTo installationaoflagger: full path to your aoflagger executable
Location of the calibrator solutions
cal_solutions: location of the calibrator solutions (default:input.output.job_directory/../Pre-Facet-Calibrator/results/cal_values/cal_solutions.h5, if you stick to the defaults)
Parameters you may need to adjust
Data selection and calibration options
refant:name of the station that will be used as a reference for the phase-plotsflag_baselines: NDPPP-compatible pattern for baselines or stations to be flagged (may be an empty list, i.e.:[])process_baselines_target: performs A-Team-clipping/demixing and direction-independent phase-only self-calibration only on these baselines. Choose [CR]S*& if you want to process only cross-correlations and remove international stations.filter_baselines: selects only this set of baselines to be processed. Choose [CR]S*& if you want to process only cross-correlations and remove international stations.do_smooth: enable or disable baseline-based smoothing (may enhance signal-to-noise for LBA data)rfistrategy: strategy to be applied with the statistical flagger (AOFlagger), default:HBAdefault.rfisinterp_windowsize: size of the window over which a value is interpolated. Should be odd. (default: 15)raw_data: use autoweight, set to True in case you are using raw data (default: False)compression_bitrate: defines the bitrate of Dysco compression of the data after the final step, choose 0 if you do NOT want to compress the datamin_unflagged_fraction: minimal fraction of unflagged data to be accepted for further processing of the data chunkpropagatesolutions: use already derived solutions as initial guess for the upcoming time slot
A comprehensive explanation of the baseline selection syntax can be found here.
Demixing options (only used if demix step is added to the prep_targ_strategy variable)
demix_sources: choose sources to demix (provided as list), e.g.,[CasA,CygA]demix_target: if given, the target source model (its patch in the SourceDB) is taken into account when solving (default:"")demix_freqstep: number of channels to average when demixing (default: 16)demix_timestep: number of time slots to average when demixing (default: 10)
Definitions for pipeline options
initial_flagging: choose {{ raw_flagging }} if you process raw datademix_step: choose {{ demix }} if you want to demixapply_steps: comma-separated list of apply_steps performed in the target preparation (NOTE: only use applyRM if you have performed RMextract before!)clipAteam_step: choose {{ none }} if you want to skip A-team-clippinggsmcal_step: choose tec if you want to fit TEC instead of self-calibrating for phasesupdateweights: update the weights column, in a way consistent with the weights being inverse proportional to the autocorrelations
Parameters for pipeline performance
num_proc_per_node: number of processes to use per step per node (default:input.output.max_per_node, reads the parametermax_per_nodefrom thepipeline.cfg)num_proc_per_node_limit: number of processes to use per step per node for tasks with high I/O (DPPP or cp) or memory (e.g. calibration) (default: 4)max_dppp_threads: number of threads per process for NDPPP (default: 10)min_length: minimum amount of chunks to concatenate in frequency necessary to perform the wide-band flagging in the RAM. It data is too big aoflag will use indirect-read.overhead: Only use this fraction of the available memory for deriving the amount of data to be concatenated.min_separation: minimal accepted distance to an A-team source on the sky in degrees (will raise a WARNING)error_tolerance: defines whether pipeline run will continue if single bands fail (default: False)
Parameters you may want to adjust
Main directories
lofar_directory: base directory of your LOFAR installation (default: $LOFARROOT)job_directory: directory of the prefactor outputs (usually thejob_directoryas defined in thepipeline.cfg, default:input.output.job_directory)
Script and plugin directories
scripts: location of the prefactor scripts (default:{{ prefactor_directory }}/scripts)pipeline.pluginpath: location of the prefactor plugins: (default:{{ prefactor_directory }}/plugins)
Sky model directory
A-team_skymodel: path to A-team skymodel (used for demixing and clipping)target_skymodel: path to the skymodel for the phase-only calibration of the targetuse_target: download the phase-only calibration skymodel from TGSS, “Force” : always download , “True” download if {{ target_skymodel }} does not exist , “False” : never downloadskymodel_source: use GSM if you want to use the experimental (!) GSM SkyModel creator using TGSS, NVSS, WENSS and VLSS
Result directories
results_directory: location of the prefactor results (default:{{ job_directory }}/results)inspection_directory: location of the inspection plots (default:{{ results_directory }}/inspection)cal_values_directory: directory of the calibration solutions (h5parm file, default:{{ results_directory }}/cal_values)
Location of calibrator solutions
solutions: location of the calibration solutions (h5parm file, default:{{ cal_values_directory }}/cal_solutions.h5)
Averaging for the calibrator data
avg_timeresolution: intermediate time resolution of the data in seconds after averaging (default: 4)avg_freqresolution: intermediate frequency resolution of the data after averaging (default: 48.82kHz, which translates to 4 channels per subband)avg_timeresolution_concat: final time resolution of the data in seconds after averaging and concatenation (default: 8)avg_freqresolution_concat: final frequency resolution of the data after averaging and concatenation (default: 97.64kHz, which translates to 2 channels per subband)
Concatenating of the target data
num_SBs_per_group: make concatenated measurement-sets with that many subbands (default: 10)reference_stationSB: station-subband number to use as reference for grouping, (default:None-> use lowest frequency input data as reference)
RMextract settings
ionex_server: URL of the IONEX server (default: “ftp://ftp.aiub.unibe.ch/CODE/”)ionex_prefix: the prefix of the IONEX files (default: CODG)ionex_path: location of the IONEX files after downloading (default:{{ job_directory }}/IONEX/)
Recommended parameters for HBA and LBA observations¶
parameter |
HBA |
LBA |
|
False |
True |
|
HBAdefault |
LBAdefaultwideband.rfis |
|
applyclock,applybeam,applyRM |
applyphase,applybeam |
|
phase |
tec |
|
TGSS |
GSM |
|
{{ clipATeam }} |
{{ none }} |
|
||
|
97.64kHz |
48.82kHz |
|
10 |
-1 |
In case of LBA observation you might also want to enable demixing in the prep_targ_strategy variable.
If your LBA data has not been demixed before you may still want to keep the A-Team-clipping.